TinyMS的设计理念¶
背景¶
近些年随着AI技术的蓬勃发展,业界不断涌现出很多优秀的深度学习框架:比如TensorFlow、PyTorch、Apache MXNet、MindSpore等,这些框架的提出满足了各行各业进行AI模型/应用开发的需求。但是由于AI技术的门槛较高,导致原生框架的API并不能满足所有用户/开发者的需求,这也导致后期出现了许多针对AI框架而定制开发的高阶API项目:比如Keras(TF)、fastai(PyTorch)等。TinyMS是此类项目的新成员,旨在提供简单有效的高阶API、低运行开销、模块化开发以及敏捷部署。TinyMS的开发将首要聚焦在对MindSpore框架的支持,同时也欢迎开发者提供对更多框架的支持。
值得注意的是,MindSpore的高阶和中阶Python API已经实现了Keras的大部分功能,不需要再额外封装一层类似Keras的API;与fastai本身专为PyTorch灵活性而生的快速开发验证而提供的能力也不相上下。因此不同于Keras和fastai基于底层框架的特点或不足进行进一步优化的设计初衷,TinyMS着重于提升开发者对已有框架即MindSpore的使用体验,尤其是面向全场景的开发和部署。
在TinyMS的帮助下,我们希望达到如下目标:
一分钟内上手AI应用开发
一小时内掌握AI模型与数据集的自由切换
架构设计¶
TinyMS的架构目标:
极简易学的高阶API
支持从数据准备到模型训练/推理到最终部署的全流程
模块间解耦,易于扩展
可以应用在手机、边缘、云等全场景的低运行时开销支持
模型训练脚本的格式进行标准化和规范化
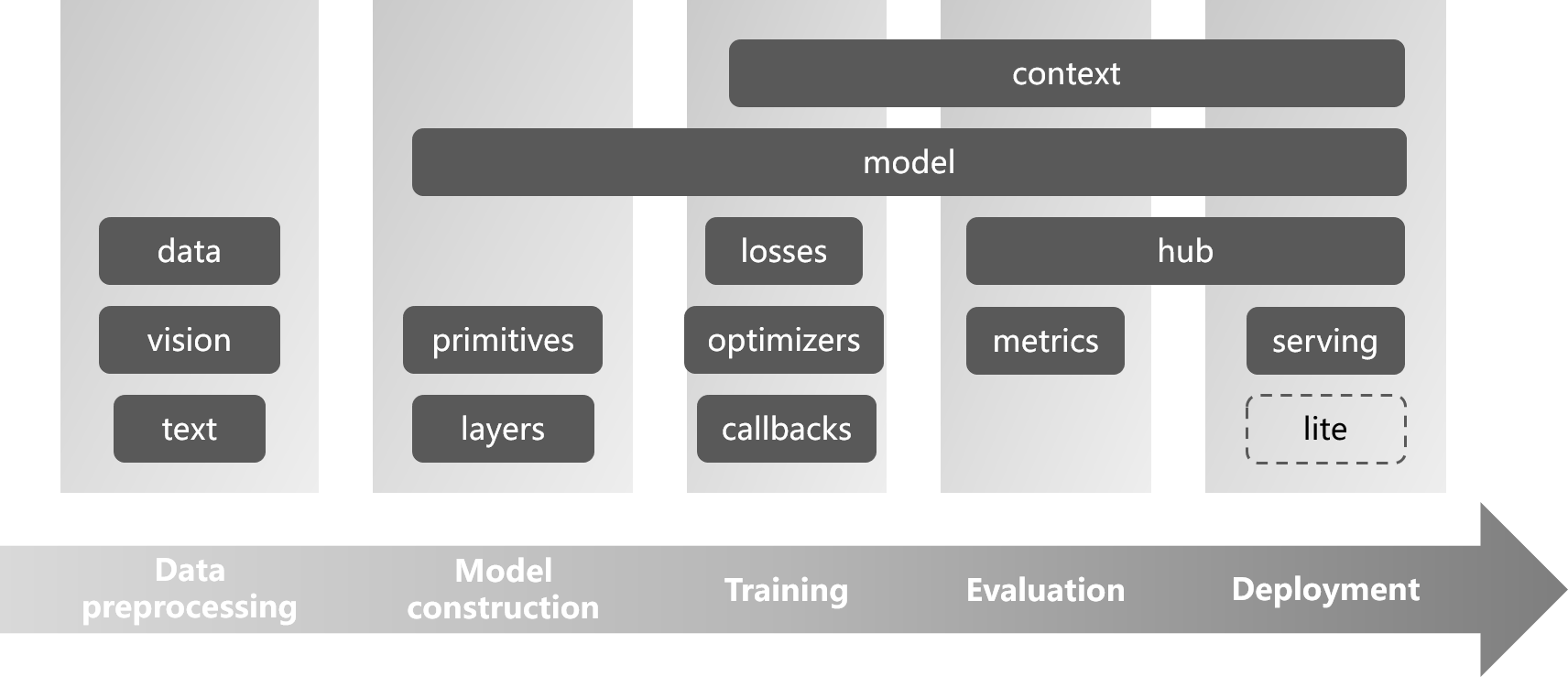 TinyMS Architecture
TinyMS Architecture
流程解析¶
对于大多数AI模型应用开发场景,基本上都可以归纳为如下几个步骤:
数据获取:包括数据集下载、解压、加载等操作
数据处理:为了能让模型获得更好的性能,一般都会针对原始数据进行数据预处理(增强)操作
模型构建:除了网络主体的构建,还包括Loss损失函数、Optimizer优化器等定义
模型训练:负责模型训练的流程,其中包括callbacks的定义
精度验证:负责模型精度验证的流程,其中包括metrics的定义
模型部署:通过搭建服务器来提供AI模型应用服务
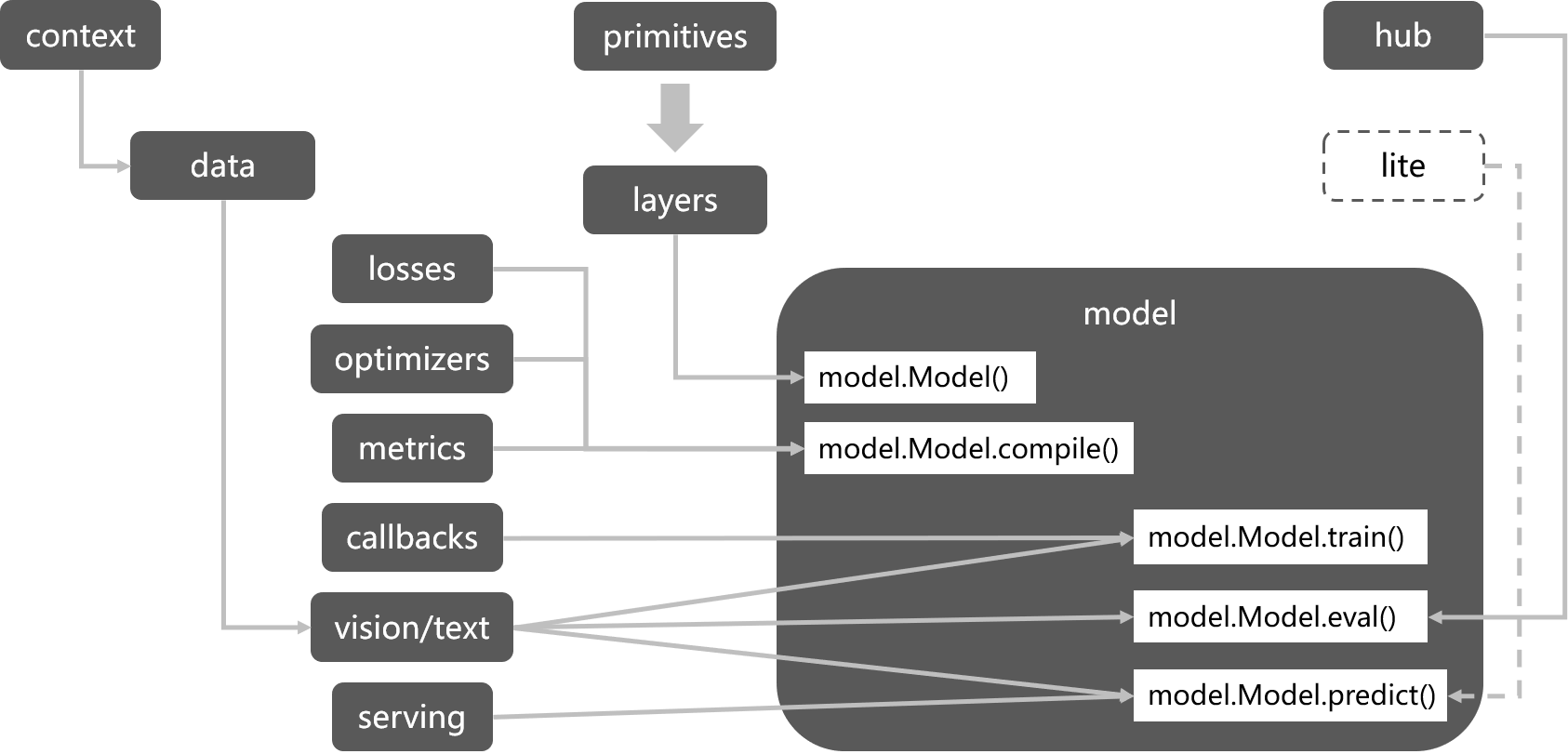 TinyMS Workflow
TinyMS Workflow
模块划分¶
针对上述场景提到的步骤,当前TinyMS创建了如下几个模块:
| 模块名称 | 功能介绍 | 样例代码 |
|---|---|---|
| app | 支持OpenCV实现模型推理可视化 | from tinyms.app import object_detection |
| data | 数据集一键下载和加载 | from tinyms.data import MnistDataset, download_dataset |
| hub | 预训练模型库,适用于模型推理和迁移学习 | from tinyms import hub |
| model | Model高阶API以及预置网络 | from tinyms.model import Model, lenet5 |
| serving | 模型部署模块 | from tinyms.serving import predict |
| vision | CV领域相关的数据处理 | from tinyms.vision import mnist_transform, Resize |
| text | NLP领域相关的数据处理 | from tinyms.text import Lookup |
| callbacks | 模型训练过程的回调处理 | from tinyms.callbacks import ModelCheckpoint |
| common | 基础组件,包括Tensor、numpy风格的函数 | from tinyms import Tensor, array |
| context | 全局上下文 | from tinyms import context |
| initializers | 算子权重初始化 | from tinyms.initializers import Normal |
| layers | 构建网络的算子清单 | from tinyms.layers import Layer, Conv2d |
| losses | 模型训练的损失函数 | from tinyms.losses import SoftmaxCrossEntropyWithLogits |
| metrics | 模型验证的指标收集 | from tinyms.metrics import Accuracy |
| optimizers | 模型训练的优化器 | from tinyms.optimizers import Momentum |
| primitives | 基础算子 | from tinyms.primitives import Add, tensor_add |
模块实现¶
看到这里相信大家对TinyS的整体架构有了初步的了解,接下来我们就每个模块的设计与实现思路逐一讲解。
数据加载(data)¶
数据加载模块主要分为数据集下载和加载两个部分,通过TinyMS的数据加载API仅需两行代码便可完成常见数据集的下载、解压、格式调整、加载等流程。
大部分AI框架不会提供数据集下载的接口,需要用户提前准备好数据集,同时要按照框架本身提供的数据加载API格式进行格式的调整(训练/验证数据集划分等),这对于AI初学者来说门槛还是相当高的。基于该问题TinyMS提供了download_dataset接口,支持用户一键完成数据集的下载、解压和格式调整操作;以Mnist手写数字数据集为例:
from tinyms.data import download_dataset
mnist_path = download_dataset('mnist', local_path='./')
对于数据加载操作,TinyMS完全继承了MindSpore原生的数据加载API,这样用户可以非常方便地使用xxxDataset接口进行不同数据集的实例化;以MnistDataset为例:
from tinyms.data import MnistDataset
mnist_ds = MnistDataset(mnist_path, shuffle=True)
数据处理(vision和text)¶
通常在构建AI模型开发应用时,数据处理是我们面临的第一大挑战:数据量不足、人为标注工作量大、数据格式不规范等问题都又可能导致训练之后的网络精度不达标,因此绝大多数AI框架都会提供数据处理的相关模块。以MindSpore为例,MindSpore当前提供CV和NLP等常用场景的数据处理功能(相关接口定义可以查阅mindspore.dataset.vision和mindspore.dataset.text),用户可以直接调用其中预设的数据处理算子对图片或文本进行处理,然后通过构建数据处理pipeline来对海量数据进行高效并行处理(详见此处)。
TinyMS在MindSpore的基础上做了进一步的抽象与封装,通过DatasetTransform接口直接对应到数据集本身的处理,让用户可以一行代码就实现单条数据或者整个数据集的预处理操作;以MnistTransform为例:
from PIL import Image
from tinyms.vision import mnist_transform
# 针对单张图片进行预处理
img = mnist_transform(Image.open('picture.jpg'))
# 针对MnistDataset实例进行预处理
mnist_ds = mnist_transform.apply_ds(mnist_ds)
网络构建(model)¶
网络结构作为深度学习模型开发的核心,AI框架的主要职责就是提供完备的算子表达用来构建不同的网络结构,因此AI框架层面的接口更侧重于功能完备度和灵活性;AI框架会专门提供ModelZoo组件,用来满足用户的使用和商业落地诉求。TinyMS在原生脚本之上封装好相关的网络调用API;以LeNet5网络为例:
from tinyms.model import lenet5
net = lenet5(class_num=10)
除了封装常用的网络结构之外,TinyMS还提供了Model高阶API接口(基于MindSpore Model接口封装),通过借鉴Keras Model接口的设计思想,不仅完善了原生API接口的功能,还为希望尝试TinyMS的Keras用户提供了一致性的开发体验:
from tinyms.model import Model
model = Model(net)
model.compile(loss_fn=net_loss, optimizer=net_opt)
模型训练(losses、optimizers和callbacks)¶
对于模型训练阶段,最重要的因素就是损失函数、优化器以及回调函数的定义,关于这三者的基本定义这里不做赘述。而对于初学者来说,了解损失函数和优化器的基本原理并不困难,但是想要了解其中的原理实现则需要较强的数学背景。因此TinyMS高阶API针对损失函数和优化器进行网络层面的封装,这样无论是训练简单或复杂的网络,用户都可以用一行代码完成初始化工作;以LeNet5网络为例:
from tinyms.losses import SoftmaxCrossEntropyWithLogits
from tinyms.optimizers import Momentum
lr = 0.01
momentum = 0.9
net_loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
net_opt = Momentum(net.trainable_params(), lr, momentum)
关于回调函数的定义,除了常用的回调函数外(比如TimeMonitor、LossMonitor等),MindSpore本身提供了Callback接口以方便用户自定义回调函数。而TinyMS高阶API同样提供了网络层面的封装,这样用户可以用一行代码完成回调函数的初始化工作;以MobileNetV2网络为例:
from tinyms.callbacks import mobilenetv2_cb
net_cb = mobilenetv2_cb(device_target, lr, is_saving_checkpoint, save_checkpoint_epochs, step_size)
模型精度验证(metrics)¶
模型精度验证是检验模型精度是否达标必不可少的过程,MindSpore原生提供了Accuracy、Precision等指标的度量接口(详见此处),同时为用户提供了Metric自定义度量接口。在指标度量方面TinyMS直接继承了原生MindSpore API,用户可以沿用MindSpore的习惯来进行精度验证:
from tinyms.model import Model
from tinyms.metrics import Accuracy
model = Model(net)
model.compile(metrics={"Accuracy": Accuracy())
预训练模型加载(hub)¶
TinyMS Hub是TinyMS生态的预训练模型应用工具,作为模型开发者和应用开发者的管道:
向模型开发者提供方便快捷的模型发布、提交通道;
向应用开发者提供高质量的预训练模型,结合模型加载以及模型Fine-tune API快速完成模型的迁移到部署的工作。
TinyMS Hub提供的预训练模型主要包括图像分类、目标检测、语义模型、推荐模型等。
当前hub模块为开发者提供了多种加载预训练模型的接口:
加载预训练模型
from PIL import Image from tinyms import hub from tinyms.vision import mnist_transform from tinyms.model import Model img = Image.open(img_path) img = mnist_transform(img) # load LeNet5 pre-trained model net= hub.load('tinyms/0.2/lenet5_v1_mnist', class_num=10) model = Model(net) res = model.predict(ts.expand_dims(ts.array(img), 0)).asnumpy() print("The label is:", mnist_transform.postprocess(res))
加载模型ckpt文件
from tinyms import hub from tinyms.model import lenet5 from tinyms.utils.train import load_checkpoint ckpt_dist_file = '/tmp/lenet5.ckpt' hub.load_checkpoint('tinyms/0.2/lenet5_v1_mnist', ckpt_dist_file) net = lenet5() load_checkpoint(ckpt_dist_file, net=net)
加载模型权重
from tinyms import hub from tinyms.model import lenet5 from tinyms.utils.train import load_param_into_net param_dict = hub.load_weights('tinyms/0.2/lenet5_v1_mnist') net = lenet5() load_param_into_net(net, param_dict)
模型部署推理(serving)¶
模型部署推理是指将预训练好的模型服务化,使其快速、高效地对用户输入的数据进行处理,得到结果的过程。MindSpore提供了predict函数用于推理,同样的,TinyMS针对这个函数进行了相应的封装,以同一个接口对接不同的后端网络。为了实现服务化,TinyMS基于Flask提供了整套的启动服务器(start_server)、检查后端(list_servables)、检查是否启动(server_started)和关闭服务器(shutdown)等功能; 以LeNet5网络为例:
from tinyms.serving import Server, Client
server = Server()
# 启动推理服务器
server.start_server()
client = Client()
# 查看当前可用的推理模型
client.list_servables()
# 从客户端调用推理接口
client.predict(image_path, 'lenet5', dataset_name='mnist')
# 关闭推理服务器
server.shutdown()
除此之外,TinyMS还提供了WEB可视化界面,方便使用者在网页上直接上传图片进行推理,目前主要支持LeNet5、CycleGan和SSD300网络,只需启动后台推理服务器,前端服务器通过Nginx web服务器部署,项目路径存放在当前tinyms项目的tinyms/serving/web目录下。若想快速试用,可查看快速安装TinyMS Nginx版本 一节:
# WEB后端服务器启动
from tinyms.serving import Server
server = Server()
server.start_server()
模型推理可视化应用(app)¶
OpenCV是用于计算机视觉的库,TinyMS是深度学习框架的高阶API库。通常我们在训练后,需要加载预训练模型验证模型的效果时,得到的结果往往是一堆数字。这些数据对于初学者是枯燥的,不直观的,要想理解它们代表的含义是非常困难的。因此,TinyMS在0.3.0版本将模型推理可视化作为主要特性,结合OpenCV实现图像的实时监测和可视化检测,去帮助用户更直观地感受推理的效果。目前,可视化推理模块仅支持目标检测模型SSD300,未来会增加对更多图像处理模型的支持。
下面,我将演示如何使用训练过的模型来检测静态图像和电脑摄像头采集的实时动态的视频图像, 仅需5个步骤即可实现:
静态图像对象检测
import cv2
from tinyms.app.object_detection.utils.config_util import load_and_parse_config
from tinyms.app.object_detection.object_detector import ObjectDetector, object_detection_predict
from tinyms.app.object_detection.utils.view_util import visualize_boxes_on_image
# 1.加载和解析模型配置JSON文件
config_path = '**/tinyms/app/object_detection/configs/tinyms/0.3/ssd300_shanshui.json'
config = load_and_parse_config(config_path=config_path)
# 2.创建ObjectDetector类的实例
detector = ObjectDetector(config=config)
# 3.使用OpenCV读取静态图像
img_path = ('./pic/test.jpeg)
image_np = cv2.imread(img_path)
input = image_np.copy()
# 4.对图像进行检测
detection_bbox_data = object_detection_predict(input, detector, is_training=False)
# 5.调用OpenCV库为图像画检测框并显示检测图像检测效果图
detection_image_np = visualize_boxes_on_image(image_np, detection_bbox_data, box_color=(0, 255, 0),
box_thickness=3, text_font=cv2.FONT_HERSHEY_PLAIN,
font_scale=2, text_color=(0, 0, 255), font_size=3, show_scores=True)
cv2.imshow('object detection image', cv2.resize(detection_image_np, (600, 1000)))
cv2.waitKey(0)
电脑摄像头采集的视频图像实时动态检测
import cv2
from tinyms.app.object_detection.utils.config_util import load_and_parse_config
from tinyms.app.object_detection.object_detector import ObjectDetector, object_detection_predict
from tinyms.app.object_detection.utils.view_util import visualize_boxes_on_image
# 1.加载和解析模型配置JSON文件
config_path = "**/tinyms/app/object_detection/configs/tinyms/0.3/ssd300_voc.json"
config = load_and_parse_config(config_path=config_path)
# 2.创建ObjectDetector类的实例
detector = ObjectDetector(config=config)
cap = cv2.VideoCapture(0)
while True:
# 3.使用OpenCV读取摄像头每帧图像
ret, image_np = cap.read()
input = image_np.copy()
# 4.对每帧图像进行检测
detection_bbox_data = object_detection_predict(input, detector, is_training=False)
# 5.调用OpenCV库为每帧图像画检测框并显示动态视频图像检测效果图
detection_image_np = visualize_boxes_on_image(image_np, detection_bbox_data, box_color=(0, 255, 0),
box_thickness=3, text_font=cv2.FONT_HERSHEY_PLAIN,
font_scale=2, text_color=(0, 0, 255), font_size=3, show_scores=True)
cv2.imshow('object detection camera', cv2.resize(detection_image_np, (800, 600)))
if cv2.waitKey(25) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()